


OSINT significa Open Source Intelligence (inteligencia sobre fuentes de información abiertas, es decir, sacar información de “cosas” que uno se encuentra en Internet) y es uno de los aspectos clave para comprender la ciberseguridad que rige Internet hoy en día.
Hacer investigaciones con este tipo de información abierta implica hacerse muchas preguntas sobre los individuos o entidades que se estudian (en adelante, objetivos) y dar una respuesta más o menos precisa a ellas, en función de la información que se encuentre (o que se pueda inferir) de los objetivos. Para ello se deben hacer una serie de actividades que, a ojo de una persona que crea que la seguridad tiene un componente altamente técnico, pueden ser sorprendentes o consideradas “no serias”. Pero nada más lejos de la realidad.
En un mundo cada vez más y más interconectado, los delitos basados en el mal uso de información expuesta (normalmente de forma indebida) no van a ir a menos, sino todo lo contrario. Estos delitos ocurrirán (y ya ocurren) sobre personas, empresas y los productos software que ambas entidades usan. Nadie se libra, y la única “vacuna” es estar lo más formado y alerta posible, aunque nada es infalible. Trabajar con esta clase de información es el medio favorito para recopilar información que desencadene ataques de phishing y / o spear phishing muy efectivos, que han hecho caer gigantes. Para muestra la brecha de Febrero de 2023 de Reddit. Y tantas, tantas otras que han pasado y pasarán.
¿Por qué? Porque tradicionalmente hemos concentrado nuestros esfuerzos en defender máquinas e infraestructuras, lo cual está muy bien y es muy necesario. Pero quizá no le hemos dedicado el mismo esfuerzo a defender a las personas. Y esas personas son los usuarios que operan esas máquinas e infraestructuras. Y tienen un perfil de conocimientos técnicos extremadamente variable. Y son el eslabón más débil. El error humano es el responsable del 82% de las brechas de datos [1]. Si estás leyendo esto, puede que te estés preguntando ¿estoy preparado para eso? Mucha gente descubre (demasiado tarde) que no. Y no estoy hablando de gente que estudia ingenierías informáticas o afines: esto afecta a todo aquel que use un dispositivo conectado a Internet.
El delito del doxing
No debe confundirse las investigaciones basadas en OSINT con el doxing. Este es un tipo de ataque cibernético (es decir, un delito) en el que el atacante roba la información personal del objetivo y la filtra a Internet. Por lo general, el objetivo del doxing es acosar o dañar a la víctima de alguna manera. Las variantes dependen del contexto y la víctima, y son tantas que no es posible enumerarlas aquí.
Desafortunadamente, el doxing es más común de lo que piensas. Todo tipo de personas son potenciales víctimas, no importa si eres o no famoso. Hay gente “mala” por ahí fuera que puede querer hacerte daño a ti o a los tuyos por alguna razón (envidia, supuesta “superioridad moral”, no considerarte “digno” de algo, por pertenecer a un colectivo determinado (edad, empresa, ideología, ...), hay miles de razones...). A veces, esta parte de la informática enlaza fácilmente con temas de siquiatría o sicología.
En cierto sentido ambas operaciones están relacionadas. En ambos casos se intenta obtener toda la información posible sobre un objetivo, pero en el caso del OSINT se hace con fuentes abiertas, o dicho de otra forma, información de libre acceso. Esto implica que se hace de manera legal, salvo si luego usamos esa información para extorsionar o causar alguna clase de daño a la víctima. En el caso del doxing se hace de fuentes restringidas o no públicas a las que se tiene acceso de alguna forma, lo que lo hace una actividad ilegal. ¿Motivo? Acceder a y/o divulgar información privada de una persona es un delito.
Para defendernos contra esto no queda más remedio que pensar como los delincuentes. Sin saber las “armas” con las que cuenta el enemigo, difícilmente podremos a) establecer contramedidas que funcionen y b) detectar puntos vulnerables a dichas “armas” del enemigo. En general, para evitar el doxing, es muy importante tener mucho cuidado con el tipo de información que expones en Internet. Y, muchas veces, no queda otro remedio para saber qué se podría robar que simular ser un adversario. Tu propio adversario.
¿Qué clase de información se recoge?
En esta clase de investigaciones siempre se trata de saber cosas del objetivo que luego puedan usarse para desencadenar ataques (phishing que implique suplantación o convencer al objetivo de algo, averiguar credenciales, suplantar a alguien...) u obtener cualquier clase de ventaja táctica o estratégica sobre dicho objetivo. Esto incluye aspectos como los siguientes:
- Nombre real / apellido
- Amistades / familia / relaciones...
- Características físicas (peso, altura...), aficiones, hobbies, gustos personales, orientación sexual...
- Direcciones de correo electrónico: destino de ataques vía phishing
- Números de teléfono (con los que tener acceso vía mensajería instantánea)
- Perfiles en redes sociales y todo lo que se cuenta o se muestra (fotos/videos) en ellas (que es mucho más de lo que imaginas). ¿Sabes que existen herramientas que son capaces de leer toda esa información, organizarla, permitir hacer búsquedas, filtrados, etc. sobre la cuenta de cualquiera en cualquier red social?
- Dirección o ubicación en distintas instantes de tiempo (rutinas, lugares que frecuentas...)
- Empleos (actuales y pasados, típico de LinkedIn, por ejemplo)
- Información de cuentas bancarias, tarjetas de crédito, DNI...
- Información pública sobre ti o tus negocios (BOE, BORME, BOPA, Catastro...)
- Opiniones sobre determinados asuntos, ideologías, fe religiosa...te sorprendería la cantidad de cosas que la gente confiesa sin querer amparada en el “supuesto anonimato” de las redes.
- ...
Si esta información se obtiene de forma legal hay que seguir los “mandamientos“ de la recopilación de inteligencia de fuentes abiertas u OSINT. Son cuatro:
- Open-Source
- Público
- Gratuito
- Legal
Es decir:
- Debe ser inteligencia objetiva, libre de sesgos. Por ejemplo, si es la opinión de alguien en una red social de algo, debe ser contrastada con una o varias fuentes fiables para evitar caer en bulos o fake news.
- Los datos deben estar disponibles en fuentes públicas, como las disponibles en Internet, aunque el término no se limita estrictamente a Internet, sino que incluye todas las fuentes disponibles públicamente (físicas o digitales) donde el auditor (investigador OSINT) pueda obtener la información. Debe poder obtenerse de forma gratuita, salvo casos muy concretos justificados. No importa si se encuentra dentro de periódicos, blogs, páginas web, tweets, redes sociales, imágenes, podcasts, videos...siempre y cuando sea público, gratuito y legal.
Con la información correcta se puede obtener una gran ventaja en operaciones de reconocimiento y acelerar cualquier investigación de la empresa / personas objetivo. Aunque se suele asociar el OSINT a la guerra cibernética, ataques cibernéticos, la ciberseguridad, etc. (y ciertamente es parte de ello), y por ello parecen acciones realmente complejas, las operaciones para buscar entre este tipo de información suelen ser muy poco complicadas una vez conocidas las técnicas, las herramientas y qué buscar a partir de cada información encontrada. Para muestra de lo que hay que hacer tenemos estas operaciones:
- Hacer preguntas de muchos tipos en cualquier motor de búsqueda. Sí, esto incluye los motores - chat modernos basados en IA como ChatGPT o Bing Search. Puedes preguntarle datos de una persona y seguramente sea capaz de darte una respuesta veraz y coherente en bastantes casos, con información ampliada de la misma.
- Investigar foros públicos, blogs o redes sociales (identificándolos previamente) sobre el comportamiento de una determinada persona en ellos, para ver qué cosas cuenta, revela, “se le escapan” o admite conocer creyendo que lo hace anónimamente. La gente suele revelar muchas cosas en estas situaciones.
- Investigar documentos públicos acerca de cosas que le hayan pasado al objetivo (concesiones de becas, premios, proyectos, multas, impagos...).
- Investigar si tiene alguna posesión o propiedad a su nombre (coches, casas en venta…)
- Cualquier información cotidiana que creamos que nos pueda servir para nuestros fines
- Nombres completos de los empleados, los roles de trabajo y el software que utilizan
- Datos antiguos almacenados en caché de Google / Wayback Machine: a menudo revela información interesante.
- Números de teléfono, direcciones de correo, redes sociales o resultados de Google.
- Fotografías y videos en sitios sociales comunes para compartir fotos
- Google Maps y similares para recuperar imágenes de la ubicación geográfica de los usuarios.
- ...
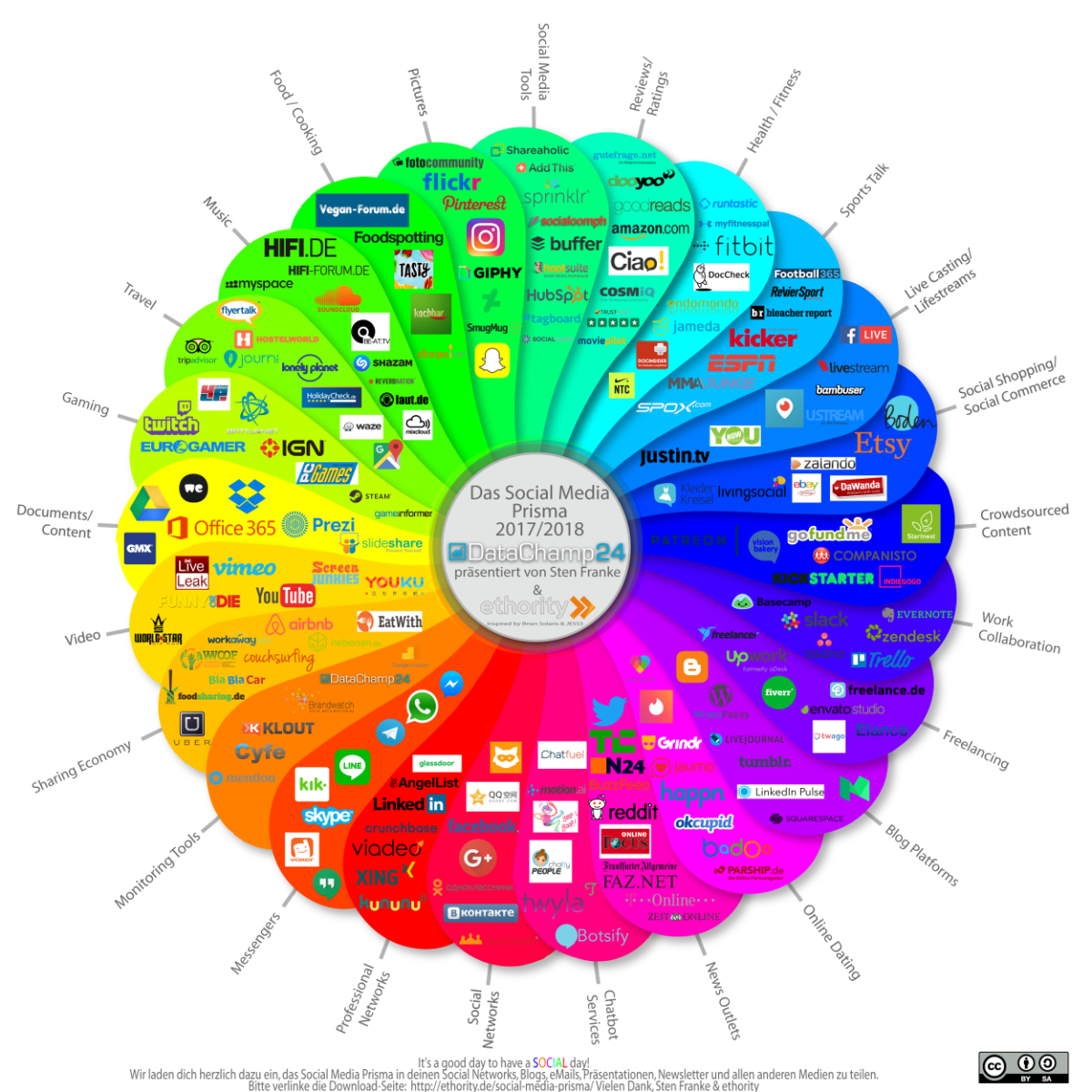
Fuentes de datos no nos van a faltar (fíjate en la siguiente imagen cuántas hay), ahora hay que saber cómo buscarlas y qué buscar. Pero tampoco creas que este tipo de operaciones ocurren de forma aislada: hay ya unas metodologías de investigación probadas y documentadas a las que cualquiera con un mínimo de interés puede acceder fácilmente. Y aplicaciones que organizan, representan, permiten manipular fácilmente y extienden esa información recopilada (como la conocida Maltego) que facilitan estos trabajos y permiten extraer más información en menos tiempo. Esto es una profesión, y como tal, hay gente haciéndola muy profesional...tanto del lado de los “buenos” como de los “malos”.
La pregunta es ¿estás tú preparado para ello? ¿has pensado en formarte? ¿y en tu empresa? ¿sabe tu empresa exactamente el riesgo al que esta expuesta por ofrecer demasiada información en Internet sin darse cuenta? Estas preguntas y otras similares deberían hacerse cuanto antes en el seno de cualquier empresa. Y en el estado en el que están las cosas hoy en día, hoy mejor que mañana.
Son demasiadas preguntas que no deberíamos dejar sin responder ni nosotros como persona individual (el egosurfing, buscarse a uno mismo en Internet a ver qué se encuentra, es una costumbre muy sana) ni, por supuesto cualquier negocio o industria. Es mucho mejor que lo hagamos nosotros primero (y pongamos remedio a lo que haya que remediar) que otros que lo único que van a apreciar de nosotros es cuanto vamos a pagarles cuando nos tengan entre la espada y la pared. Y entonces, por desgracia, ya es demasiado tarde.
[1] Fuente: https://www.grcelearning.com/blog/human-error-is-responsible-for-85-of-data-breaches











